
Python爬虫Scrapy
1.简介
1.1Scrapy
Scrapy是一个用于Web数据抓取的强大开源框架,主要用于从网站上抓取结构化数据,如HTML和XML文件,或者API返回的数据。Scrapy使用Python语言编写,它不仅仅是一个简单的网页抓取工具,而是包含了自动化、灵活的数据处理、数据存储等功能的完整框架。Scrapy的设计理念是模块化和可扩展的,支持中间件、Item Pipelines、信号和事件,以及多种数据输出格式,如JSON、XML和CSV等。
Scrapy 官网:https://scrapy.org/
Scrapy 文档:https://docs.scrapy.org/en/latest/
GitHub:https://github.com/scrapy/scrapy/
1.2架构图
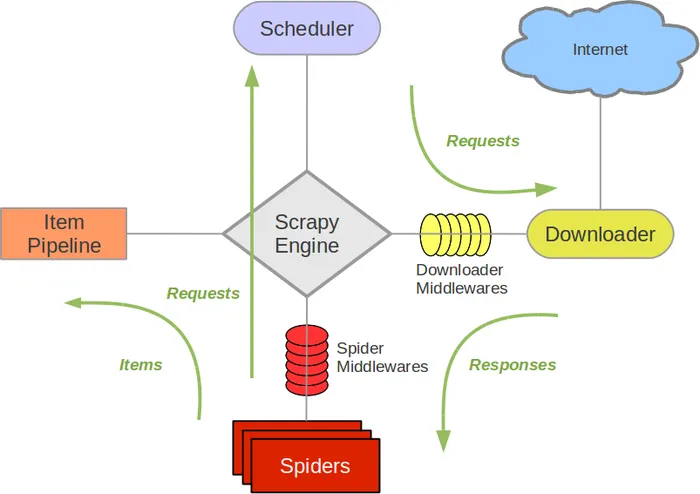
Scrapy的架构设计是模块化的,由多个组件构成,它们协同工作完成数据抓取任务。以下是Scrapy架构的主要组成部分:
- Scrapy Engine(引擎):
- 负责协调数据流在Scrapy的所有组件中流动,包括Spider、Item Pipeline、Downloader和Scheduler。
- Scheduler(调度器):
- 接收Scrapy Engine传来的Requests,并按照一定的顺序将它们入队,当Engine请求新的Requests时提供。
- Downloader(下载器):
- 负责下载由Scheduler提供的Requests,并返回Response对象。
- Spiders(蜘蛛):
- Spider是定义如何从网站上抓取数据的核心组件,它负责解析响应,提取数据(Items),以及生成新的Requests。
- Item Pipeline(项目管道):
- 用于处理由Spider提取的Items,如数据清洗、验证、存储等。Pipelines按顺序执行,可以实现复杂的数据处理逻辑。
- Downloader Middlewares(下载中间件):
- 位于Scrapy Engine和Downloader之间的层,用于处理Request和Response对象,如添加headers、处理异常、限制速度等。
- Spider Middlewares(蜘蛛中间件):
- 位于Scrapy Engine和Spider之间的层,用于处理由Spider生成的Responses和Requests,如过滤重复的Requests。
1.3逻辑流程
- 请求(Request):Scrapy的爬虫会生成一个或多个Request对象,这些对象包含了待抓取页面的URL和其他相关信息,如headers和cookies。
- 下载(Download):Scrapy的下载器(Downloader)会处理这些Request,下载页面的内容。
- 响应(Response):下载完成后,下载器会生成一个Response对象,这个对象包含了页面的HTML源码或其他响应内容,以及请求的状态信息。
- 解析(Parse):Scrapy的爬虫会处理Response对象,使用XPath、CSS选择器或正则表达式等方法从中抽取数据,生成Item对象或新的Request对象。
- Item Pipeline:抽取的数据(Item对象)会被传递给Item Pipeline,进行进一步的处理,如数据清洗、验证、去重和存储到数据库等。
- 输出(Output):最终,数据可以被导出到不同的格式,如JSON、XML、CSV等,也可以直接存储到数据库或通过API发送到其他服务。
1.4子命令
scrapy startproject [project_name]:创建一个新的Scrapy项目。scrapy genspider [name] [domain]:生成一个新的爬虫模板。scrapy crawl [spider_name]:运行指定的爬虫。scrapy settings:显示项目的配置设置。scrapy fetch [url]:下载指定URL的页面并显示响应信息。scrapy shell [url]:启动交互式的Scrapy Shell,用于调试XPath和CSS选择器。scrapy runspider [script.py]:运行一个独立的爬虫脚本,无需创建完整的项目。scrapy list:列出项目中的所有爬虫。scrapy check:检查爬虫是否有语法错误或引用了不存在的中间件或管道。
1.5安装Scrapy库
pip install scrapy 2.代码编写
编写代码爬取豆瓣电影Top250榜单数据
2.1.创建项目
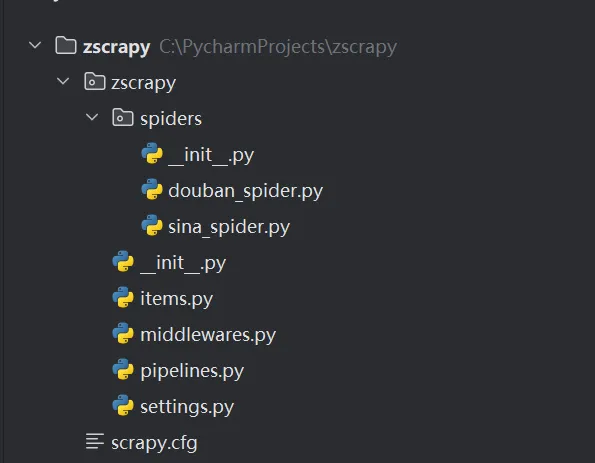
执行以下命令创建Scrapy项目,在当前目录会生成一个zscrapy目录,用于存放爬虫、中间件、管道、设置文件等组件。
scrapy startproject zscrapy 目录结构
- __init__.py: Python包的初始化文件。
- items.py: 定义项目中使用的数据项(Items)的文件。
- middlewares.py: 定义项目的中间件的文件。
- pipelines.py: 定义项目的管道(Pipelines)的文件。
- settings.py: 项目的配置文件,用于设置各种参数。
- spiders: 存放爬虫文件的子目录
2.2.定义Item
在Scrapy中,Items用于定义你从网页上抓取的数据结构。Items本质上是包含字段的容器,这些字段通常代表了你想要从网页中提取的数据。
import scrapy
class DoubanItem(scrapy.Item):
pic = scrapy.Field() # 电影图片
ranking = scrapy.Field() # 电影排名
title = scrapy.Field() # 电影名字
movieInfo = scrapy.Field() # 电影的描述信息,包括导演、主演、电影类型等等
star = scrapy.Field() # 电影评分
quote = scrapy.Field() # 电影中最经典或者说脍炙人口的一句话
pass
# 定义新闻数据的字段
class SinaNewsItem(scrapy.Item):
title = scrapy.Field() # 新闻标题
ctime = scrapy.Field() # 新闻发布时间
url = scrapy.Field() # 新闻原始url
raw_key_words = scrapy.Field() # 新闻关键词(爬取的关键词)
content = scrapy.Field() # 新闻的具体内容
cate = scrapy.Field() # 新闻类别 2.3.编写爬虫脚本
用于抓取豆瓣电影Top 250榜单的信息
# 导入Scrapy模块和系统模块
import scrapy
# 导入Scrapy的Request类,用于发送HTTP请求
from scrapy.http import Request
# 导入Selector类,用于解析HTML和XML文档
from scrapy.selector import Selector
# 导入自定义的DoubanItem类,用于存储爬取到的数据
from zscrapy.items import DoubanItem
# 导入urljoin函数,用于拼接URL
from urllib.parse import urljoin
# 导入CrawlerProcess类,用于运行爬虫
from scrapy.crawler import CrawlerProcess
# 导入get_project_settings函数,用于获取项目的设置
from scrapy.utils.project import get_project_settings
# 定义了一个名为Douban的爬虫类,继承自scrapy.spiders.Spider
class Douban(scrapy.spiders.Spider):
# 设置爬虫的名称
name = "douban"
# 设置允许爬取的域名
allowed_domains = ["douban.com"]
# 设置起始URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# 初始化一个DoubanItem实例
item = DoubanItem()
# 使用Selector解析响应对象
selector = Selector(response)
# 获得所有class="item"的div元素集
Movies = selector.xpath('//div[@class="item"]')
# 将提取到的信息存储到DoubanItem实例中,并使用yield发送给Scrapy进行进一步处理或存储
for eachMovie in Movies:
pic = eachMovie.xpath('div[@class="pic"]/a/img/@src').extract()
ranking = eachMovie.xpath('div[@class="pic"]/em/text()').extract()[0]
title = eachMovie.xpath('div[@class="info"]/div[@class="hd"]/a/span/text()').extract() # 多个span标签
fullTitle = "".join(title) # 将多个字符串无缝连接起来
movieInfo =eachMovie.xpath('div[@class="info"]/div[@class="bd"]/p/text()').extract()
movieInfo = movieInfo[0].strip("\n ")
#获取评份
star = eachMovie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract()[0]
#经典输出
quote = eachMovie.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
item['pic'] = "".join(pic)
item['ranking'] = ranking
item['title'] = fullTitle
item['movieInfo'] = movieInfo
item['star'] = star
item['quote'] = quote
#print("采集数据:",item)
yield item
# 翻页读取
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 检查是否存在“下一页”链接,如果有,则构造新的请求并调用自身parse方法进行递归爬取
if nextLink:
nextLink = nextLink[0]
yield Request(urljoin(response.url, nextLink), callback=self.parse)
# 程序入口
if __name__ =="__main__":
# 创建CrawlerProcess类对象并传入项目设置信息参数
process = CrawlerProcess(get_project_settings())
# 设置需要启动的爬虫名称
process.crawl("douban")
# 启动爬虫
process.start() 2.4.设置文件
在settings.py文件中设置代理,设置的User-Agent字符串模拟了一个运行在Windows 7操作系统上特定版本的Safari浏览器。设置USER_AGENT是为了绕过网站的防爬机制。
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50' 2.5.数据库
创建数据库zscrapy,创建表douban
create database zscrapy charset utf8mb4 collate utf8mb4_general_ci;
CREATE TABLE `douban` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`title` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '电影名称',
`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '电影图片',
`movieInfo` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '描述信息',
`star` float(3, 1) NOT NULL DEFAULT 0.0 COMMENT '电影评分',
`quote` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '经典语句',
`ranking` int(0) NOT NULL DEFAULT 0 COMMENT '电影排名',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; 安装pymysql库,pymysql是一个Python的MySQL数据库驱动,允许Python程序与MySQL数据库进行交互。
pip install pymysql 在settings.py中添加MySQL连接配置
MYSQL_HOST = 'localhost' # 数据库地址
MYSQL_DBNAME = 'zscrapy' # 数据库名字
MYSQL_USER = 'root' # 数据库登录名
MYSQL_PASSWD = 'Video201@' # 数据库登录密码
# 激活ZscrapyPipeline管道,优先级301(数值越小,优先级越高)
ITEM_PIPELINES = {
'zscrapy.pipelines.ZscrapyPipeline': 301,
}
2.6.管道
Item Pipelines负责接收从爬虫传递过来的item,并对这些item执行一系列的处理,比如清洗数据、验证数据、去重、持久化数据到数据库等。以下代码定义了一个Scrapy项目中的Item Pipeline,其目的是将爬取到的数据存储到MySQL数据库中。
# 导入pymysql模块,这是一个Python的MySQL数据库驱动。
import pymysql
# 导入项目中定义的item模块,包含爬取数据的结构定义。
import zscrapy.items
# 从项目设置模块导入设置,用于获取数据库连接信息。
from zscrapy import settings
# 定义一个名为ZscrapyPipeline的类,继承自object,这是Item Pipeline的基本类
class ZscrapyPipeline(object):
# 在Python中,self是一个指向实例本身的引用,它是类的方法中的第一个参数。
# 定义初始化方法,当创建类的实例时自动调用
def __init__(self):
# 使用pymysql.connect()方法建立到MySQL数据库的连接
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 创建游标对象,用于执行SQL语句
self.cursor = self.connect.cursor()
# 定义process_item方法,该方法将由Scrapy调用,用于处理每个爬取到的item
def process_item(self, item, spider):
try:
# 检查item是否是DoubanItem类型,如果是,执行插入到douban表的SQL语句。
if isinstance(item, zscrapy.items.DoubanItem):
# 执行SQL插入语句,参数是一个SQL字符串和一个元组,元组中的值将替换SQL字符串中的占位符
self.cursor.execute(
"""insert into douban(title,pic,ranking,movieInfo,star,quote)
value (%s,%s,%s,%s,%s,%s)""",
(item['title'],
item['pic'],
item['ranking'],
item['movieInfo'],
item['star'],
item['quote']))
else:
self.cursor.execute(
"""insert into sina_news(title,ctime,url,raw_key_words,content,cate)
value (%s,%s,%s,%s,%s,%s)""",
(item['title'],
item['ctime'],
item['url'],
item['raw_key_words'],
item['content'],
item['cate']))
# 提交事务,确保数据被持久化到数据库中
self.connect.commit()
except Exception as err:
# 捕获在执行SQL语句或提交事务过程中可能出现的异常,并打印错误信息
print("数据插入==>错误信息为:" + str(err))
# 返回处理过的item,以便它可以被下一个Item Pipeline处理或直接传递给Scrapy的其他组件
return item - 本文标签: Python
- 本文链接: https://lanzi.cyou/article/10
- 版权声明: 本文由咖啡豆原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐








相关文章
关于我
